Термины
- cRESUMES (version 0.2)
- cMAPPER (version 0.2)
- cVACANCY (version 0.2)
- cPODBOR (version 0.2.1)
- cBOOLEAN (version 0.2)
- cRECSYS (version 0.2.2)
- NLP конвейер (version 0.2)
- MATH TRUE/FALSE
- Стек технологий
cRESUMES (version 0.2)
cRESUMES: Линейка скриптов для автоматического обновления/добавления резюме и генерация ML-фичей для них
Что это?
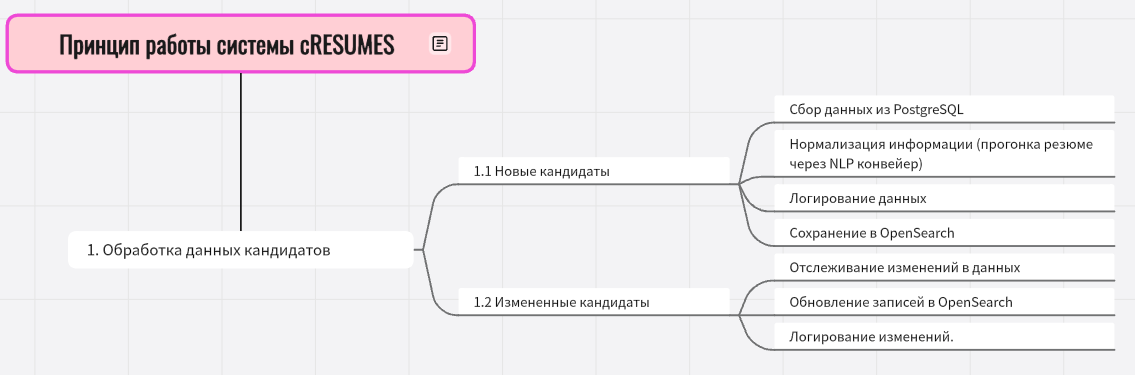
cRESUMES - глобально это скрипты, которые следитят за актуальностью резюме в системе ATS. Они проверяют базу данных каждую 1/2/3 минуты и обновляют, либо создают информацию о резюме кандидатов в OpenSearch.
Как работает?
- Проверка базы данных:
- Каждую 1/2/3 минуты обращается к PostgreSQL/OpenSearch.
- Ищет новые резюме или изменения в существующих.
- Параллельная обработка:
- Использует несколько процессов для быстрой проверки всех резюме.
- Обновление в OpenSearch:
- Если резюме уже есть в OpenSearch, проверяет, что изменилось (опыт, навыки, зарплатные ожидания, статусы) и что нужно дополнить для ML признаков.
- Обновляет только изменённые данные.
- Новые резюме добавляет в OpenSearch.
- Результат:
- Данные всегда актуальны.
- Поиск кандидатов становится быстрым и точным.
Зачем нужно?
- Держит резюме в актуальном состоянии.
- Оптимизирует поиск подходящих кандидатов.
Подробнее: см. раздел NLP конвейер.
cMAPPER (version 0.2)
cMAPPER: API для обработки и структурирования резюме
Что это?
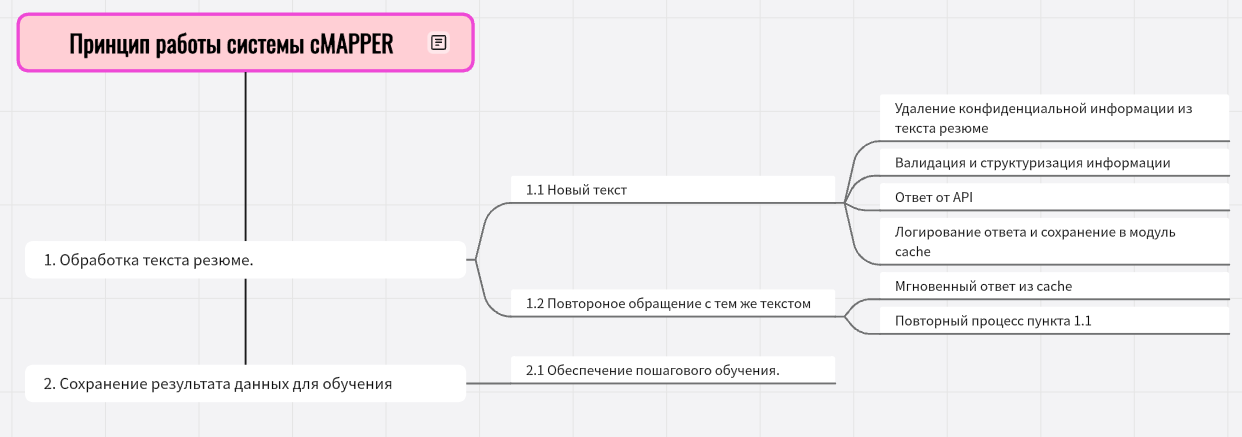
cMAPPER - это API, которое превращает текст резюме в структурированные данные. Оно помогает извлечь из резюме ключевую информацию (опыт кандидата и персональную информацию).
Доступно по ссылке: API документация.
Как работает?
- Удаление конфиденциальной информации из текста резюме
- Извлечение данных:
- Анализирует текст резюме.
- Вытаскивает информацию об опыте работы и персональных данных (навыки, пол, зарплатные ожидания, образование и т.д).
- Создание структурированных данных:
- Формирует BIO-разметку (для обучения AI-моделей).
- Создаёт JSON-файл с чёткой структурой (тоже для обучения).
- Результат:
- Превращает "сырой" текст в понятные и полезные данные.
- Упрощает оценку кандидатов для подбора на вакансии.
Особенности:
- Использует
GPT (в демо-версии)для структурирования текста.
Зачем нужно?
- Ускоряет анализ резюме и помогает находить кандидатов.
- Создает красивое системное резюме.
cVACANCY (version 0.2)
cVACANCY: Скрипт для автоматического обновления вакансий
Что это?
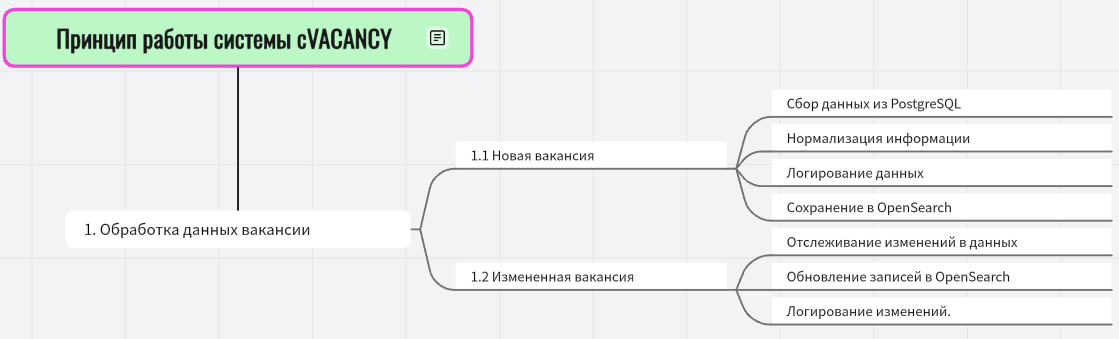
cVACANCY - это скрипт, который следит за актуальностью вакансий в системе ATS. Он автоматически проверяет базу данных и обновляет информацию о вакансиях.
Как работает?
- Проверка базы данных:
- Запускается каждые 10 минут.
- Обращается к PostgreSQL, чтобы найти новые или изменённые вакансии.
- Параллельная обработка:
- Проверяет каждую вакансию с помощью нескольких процессов.
- Обновление в OpenSearch:
- Если вакансия уже есть в OpenSearch, анализирует изменения (например, изменены зарплатные ожидания и локация).
- Обновляет только изменённые данные.
- Новые вакансии добавляет в OpenSearch.
Нормализация данных:
- Стандартизирует названия должностей (использует справочники и специальные функции
HR TECHилиGPT). - Стандартизирует навыки (использует справочники и специальные функции
HR TECHилиGPT). - Переводит зарплату в рубли (RUB).
- Кодирует математическую информацию.
- Устанавливает статус оптимизации: MATH TRUE/FALSE.
- В зависимости от заполнения вакансии распределяет их по системам RecSys/Podbor.
Зачем нужно?
- Данные о вакансиях всегда актуальны.
- Оптимизирует поиск подходящих кандидатов.
Подробнее: см. раздел MATH TRUE/FALSE
Подробнее: см. раздел cPODBOR
Подробнее: см. раздел cRECSYS
cPODBOR (version 0.2.1)
cPODBOR: Скрипт для поиска подходящих резюме
Что это?
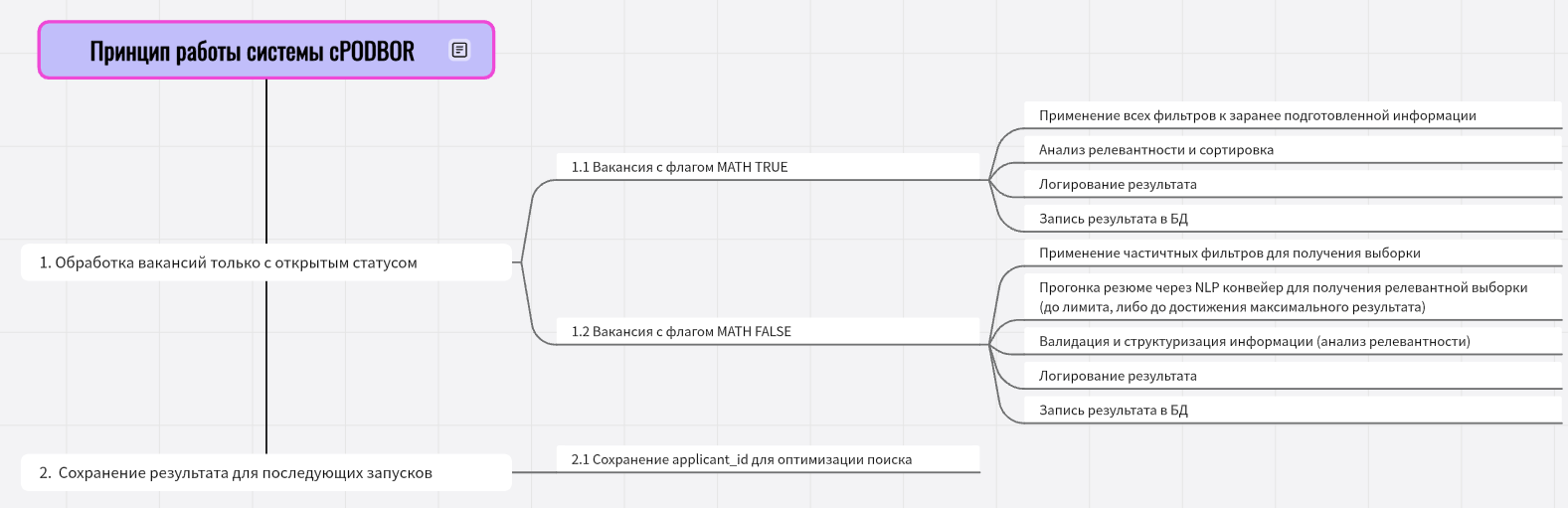
cPODBOR - это скрипт, который помогает находить подходящих кандидатов для открытых вакансий в системе ATS. Он автоматически ищет резюме, которые лучше всего подходят под вакансии, и сохраняет результаты в PostgreSQL.
Как работает?
- Запуск по расписанию:
- Каждые 20 минут обращается к OpenSearch.
- Запрашивает только открытые вакансии.
- Параллельный поиск:
- Проверяет каждую вакансию с помощью нескольких процессов.
- Сравнивает требования вакансий с данными резюме.
- Анализ кандидатов:
- Проверяет навыки, опыт и другие параметры резюме.
- Использует NLP конвейер для обработки резюме при разных значениях MATH TRUE/FALSE.
- Сохранение результатов:
- Найденные кандидаты записываются в базу данных PostgreSQL.
Зачем нужно?
- Автоматизирует поиск кандидатов.
Подробнее: см. раздел NLP конвейер
Подробнее: см. раздел MATH TRUE/FALSE
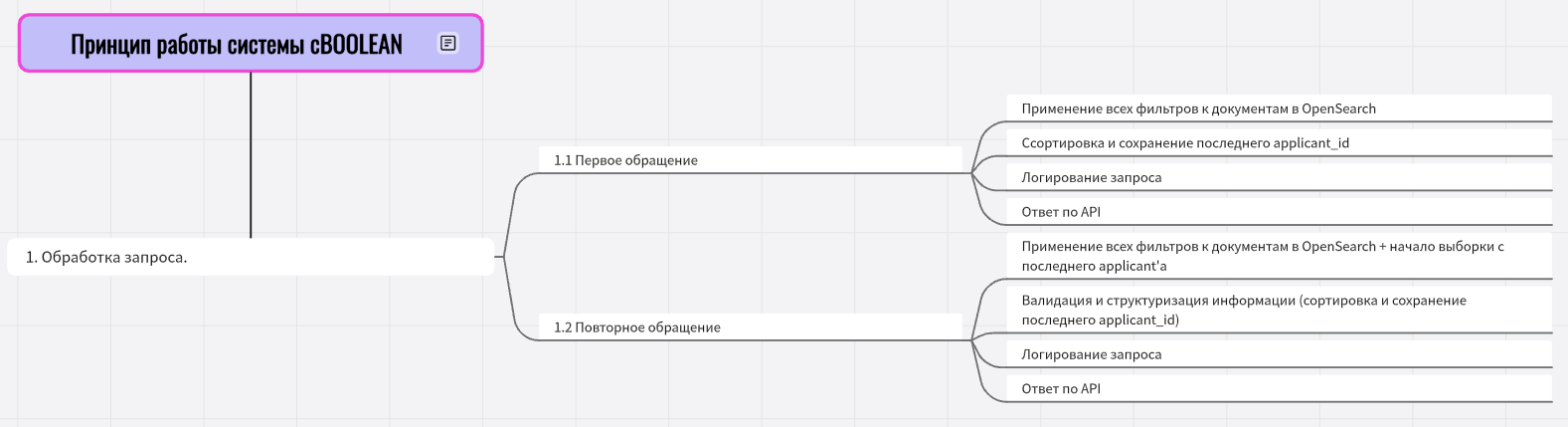
cBOOLEAN (version 0.2)
cBOOLEAN: API для булевого поиска резюме
Что это?
cBOOLEAN - это API которое позволяет искать резюме в системе ATS с помощью булевых запросов.
Доступно по ссылке: API документация.
Как работает?
- Запрос через API:
- API обрабатывает запрос и ищет подходящие резюме в базе данных.
- Поиск в ATS:
- Использует булевую логику для фильтрации резюме по навыкам, опыту и другим параметрам.
- Результат:
- Возвращает список applicant_id, которые соответствуют запросу.
Зачем нужно?
- Упрощает поиск кандидатов по сложным критериям.
- Позволяет гибко настраивать поиск с помощью булевых условий.
Подробнее: см. раздел Как улучшить свой поиск в ATS
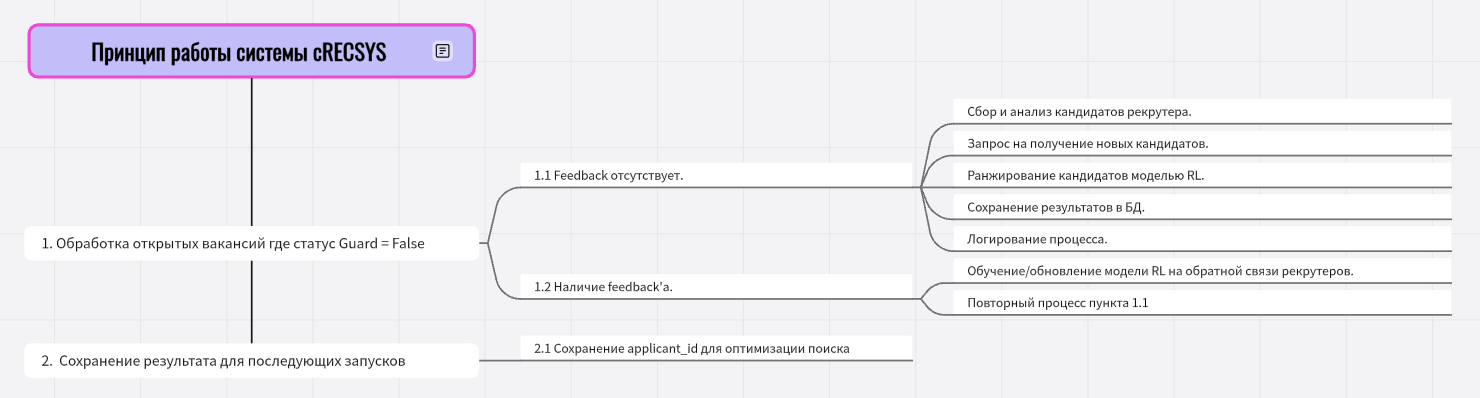
cRECSYS (version 0.2.2)
cRECSYS коллаборативная рекомендательная система.
Что это?
cRECSYS - это вспомогательный инструмент для cPODBOR с применением обучения с подкреплением (RL). Она анализирует поведение рекрутера и параметры ранее выбранных кандидатов, чтобы предсказать и рекомендовать наиболее подходящих кандидатов на вакансию.
Как работает?
- Запуск по расписанию:
- Каждые 20 минут обращается, начинается автоматизированный процесс поиска.
- Анализ вакансий:
- Отбираются только открытые вакансии.
- Сбор кандидатов рекрутера:
- Для каждой отобранной вакансии, происходит запрос в PostgreSQL для получения списка кандидатов, отобранных рекрутерами.
- Сбор и анализ параметров:
- Выполняется дополнительный запрос в OpenSearch, в ходе которого анализируются параметры и embedding'и кандидатов рекрутера.
- Обработка новых кандидатов:
- На основе полученных данных делается повторный запрос в OpenSearch для получения схожих (новых) кандидатов.
- Новые кандидаты обрабатываются моделью RL.
- Обучение на обратной связи:
- При повторых циклах модель обучается на feedback'ах рекрутера. Обучение проходит в самом начале рабочего цикла.
Тонкости cRECSYS
- Сбор пользовательской выборки:
- Получение списка кандидатов, которых рекрутер уже добавил к вакансии (из PostgreSQL).
- Анализ и агрегация параметров:
- Извлечение и анализ популярных и уникальных значений математических фильтров:
- должности в резюме
- фактический опыт
- уровень зарплаты
- возраст
- формат работы
- пол
- гражданство
- локация
- языки
- ключевые навыки и навыки в резюме
- Формирование запроса для поиска похожих кандидатов на основе агрегированных параметров (повторный запрос в OpenSearch).
- Извлечение и анализ популярных и уникальных значений математических фильтров:
-
Создание признакового пространства:
- Для каждого кандидата извлекается embedding-вектор размерностью 1024.
-
Формируется векторное представление на основе embedding'ом рассматриваемого кандидата, разницы между embedding'ом рассматриваемого кандидата и усреднёнными embedding'ами кандидатов рекрутера.
[candidate_emb, candidate_emb - mean_selected_emb]->candidate_emb + (candidate_emb - mean_selected_emb)
-
Ранжирование RL-моделью:
- Применяется агент
PPOв среде с размерностью 2048. - На основе текущего состояния (вектора признаков) агент принимает решение: отклонить кандидата (0) или выбрать его (1).
- Кандидаты ранжируются по уровню релевантности.
- Применяется агент
Механизм обучения
- Система дообучается на основе обратной связи от рекрутера при повторых запусках.
- Используется история взаимодействия:
- состояние (вектор признаков),
- действие (выбор/отказ),
- награда (оценка успешности рекомендации).
- После обучения модель сохраняется для последующих запусков.
Зачем нужно?
- Автоматизирует подбор кандидатов на основе предпочтений конкретного рекрутера.
- Учитывает как параметры резюме, так и скрытые шаблоны поведения.
- Добавляет гибкость в работе с плохими или недостаточными данными вакансии.
Подробнее: см. раздел cPODBOR
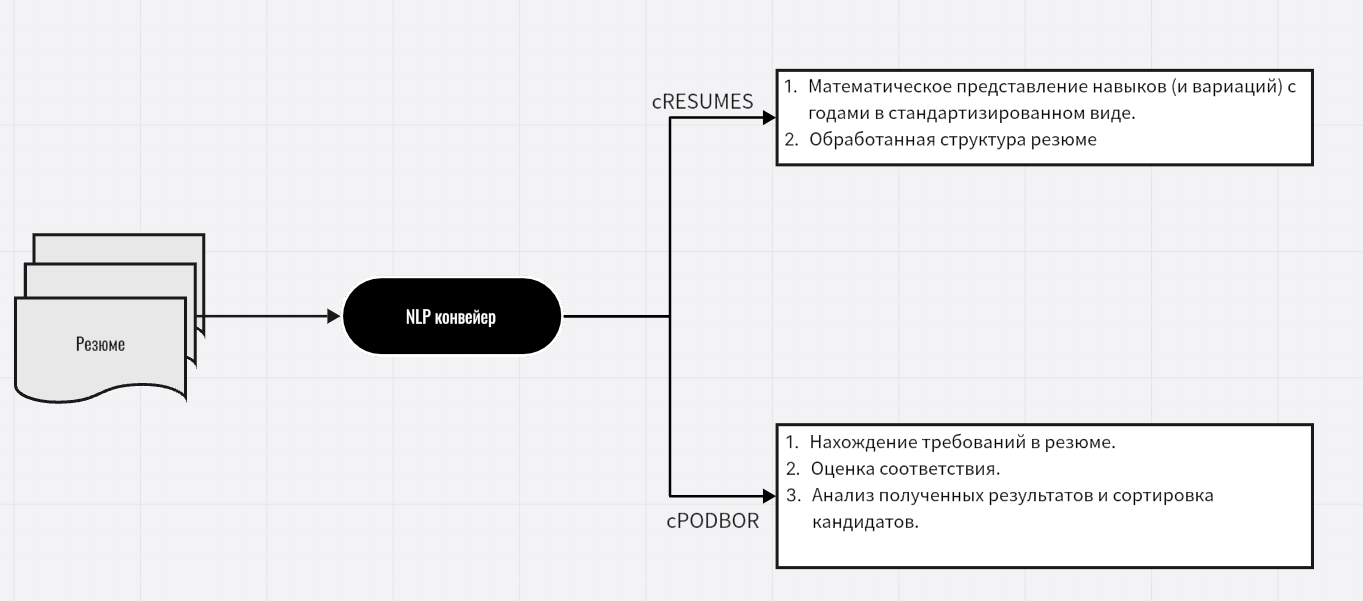
NLP конвейер (version 0.2)
NLP конвейер: Анализатор и оценщик резюме кандидатов
Что это?
NLP конвейер - это анализатор и оценщик резюме. Он выполняет две основные функции:
- В cPODBOR: сопоставляет резюме кандидатов с требованиями вакансий, отбирая подходящих кандидатов.
- В cRESUMES: приводит резюме к единому стандарту, анализируя и структурируя данные.
Анализатор использует обработку текста, анализ синонимов, FastText для семантического поиска, multilingual-e5-base для создания контекстуального эмбеддинга и многопроцессорную/многопоточную обработку, обеспечивая точный и быстрый анализ резюме.
Как работает?
Запуск по запросу:
- Активируется для обработки массива резюме из PostgreSQL/OpenSearch.
- Использует многопроцессорную/многопоточную обработку для повышения производительности.
Этапы работы
- Определение языка: Выявляет язык текста резюме.
- Форматирование данных: Преобразует данные резюме (опыт работы, навыки, должности) в единый текстовый формат.
- Анализ навыков и опыта:
- Проверяет наличие указанных навыков, их синонимов.
- Использует FastText для поиска семантически близких навыков.
- Вычисляет опыт в месяцах, учитывая текущий и прошлый опыт работы.
Завершающие действия в:
- Оценка соответствия: Сравнивает навыки и опыт кандидата с требованиями вакансии.
- Фильтрация кандидатов: Формирует список подходящих кандидатов.
- Создание контекстуального эмбеддинга из опыта резюме (размерность вектора эмбединга 768)
- Получение стандартизированного резюме
Зачем нужно?
- Оптимизирует поиск подходящих кандидатов.
- Детальный отбор кандидатов в условиях MATH FALSE (за счёт учёта синонимов, семантической близости навыков), исключение резюме, не соответствующие требованиям.
Подробнее: см. раздел cPODBOR.
Подробнее: см. раздел cRESUMES.
Подробнее: см. раздел MATH TRUE/FALSE.
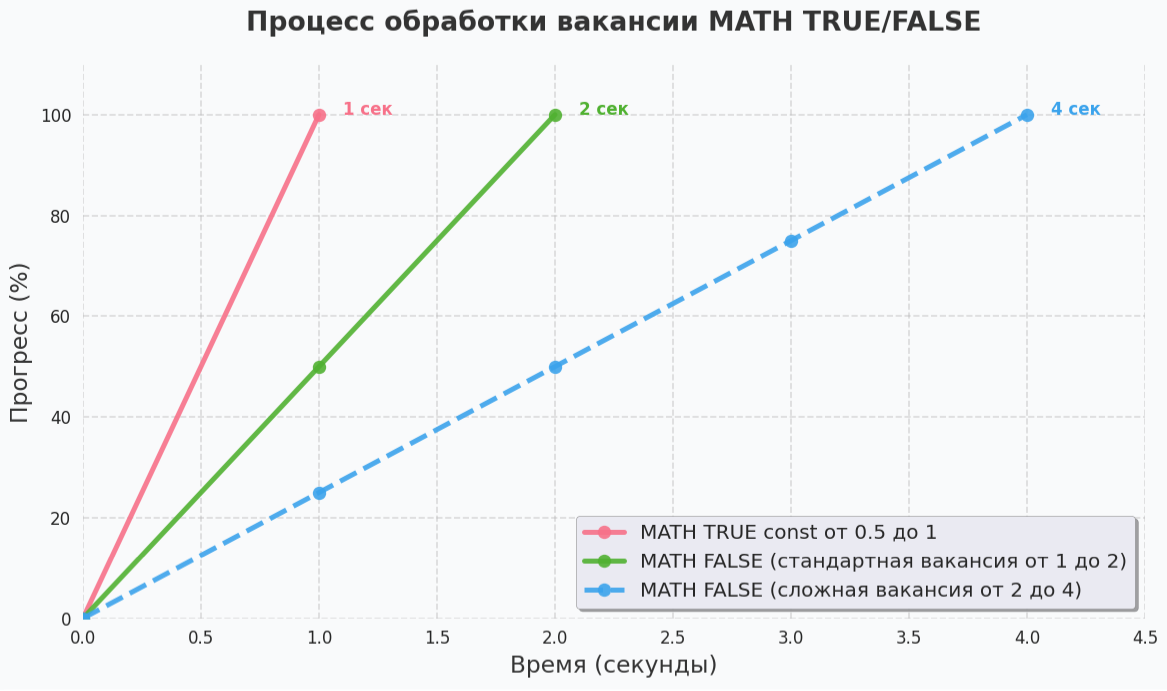
MATH TRUE/FALSE
Мы анализируем каждую вакансию с помощью cVACANCY и присваиваем ей флаг MATH: TRUE или MATH: FALSE.
MATH TRUE - всё по полочкам
Когда с помощью базы знаний и инструментов HR TECH система смогла полностью стандартизировать вакансию: все навыки, требования и параметры приведены к единому стандарту.
MATH FALSE - нужно покопаться
Когда система не смогла полностью стандартизировать параметры вакансии (например, навыки) с помощью базы знаний и инструментов HR TECH.
Но всё равно получила общее представление о вакансии и выделила новые параметры.
Что будет с MATH TRUE?
- Резюме (в OpenSearch) хранятся в стандартизированном виде, так что cPODBOR будет моментально находить подходящих кандидатов без дополнительной обработки через NLP конвейер, что позволяет эффективно распределять нагрузку и ускоряет поиск кандидатов.
Что будет с MATH FALSE?
- Система ищет резюме по тем параметрам, которые ей понятны, а новые данные отправляет на обработку через NLP конвейер, чтобы детально проверить резюме на соответствие.
Подробнее: см. раздел NLP конвейер
Подробнее: см. раздел cVACANCY
Подробнее: см. раздел cPODBOR
Стек технологий
Язык программирования
Python
Обработка естественного языка (NLP)
spaCyGensimNLTKNatashaGoogleTransLangdetect
Машинное обучение и анализ данных
Scikit-LearnSentenceTransformerPyTorchNumPyGymPPO
Визуализация
MatplotlibSeaborn
Веб-разработка и API
FastAPIFlask
Асинхронные задачи и очереди
CeleryRedis
Работа с данными и поиск
PsycopgOpenSearch
Контейнеризация
Docker
Модели
FastTextBAAI/bge-m3PPONER-T5 (находится на этапе сбора данных и обучения)NER-SpaCy (находится на этапе сбора данных и обучения)OpenAI
